Generalization, Consistency, and Stability of Large-Scale Models
Generalization · Consistency · Stability
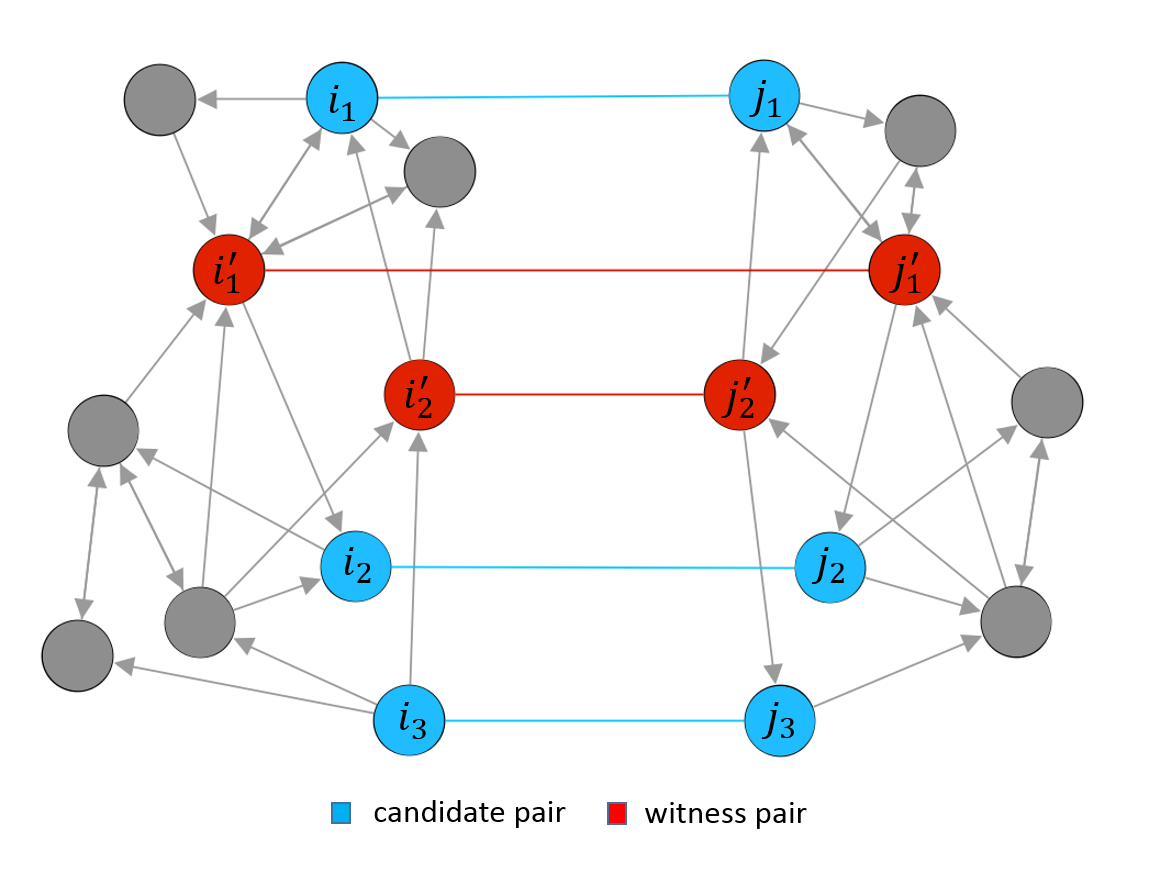
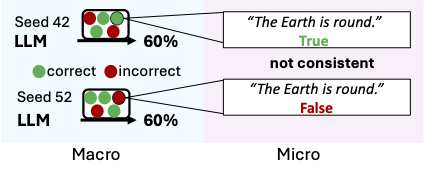
Bridging the gap between training environments and real-world deployment. Large-scale models often exhibit brittle behaviors under adversarial inputs or shifting data streams. We engineer solutions that enforce strict output consistency and improve stability during fine-tuning and lifelong learning, transforming black-box predictors into trustworthy systems for high-stakes domains.